
1.BeautifulSoup Modülü Nedir ?

BeautifulSoup, HTML veya XML dosyalarını işlemek için oluşturulmuş güçlü ve hızlı bir kütüphanedir.
Requests modülü internet sitelerine istekte bulunma işlemine yarar. Requets modülü tarayıcı gerekmeksizin sitelere istek yapabilir.İstek sonucunda bize sitenin html kodlarını döndürür.
Beautifulsoup modülü ise request modülü ile gelen html kodlarını düzenli bir şekilde göstermeye yarar.
Bu modüller python kurulumu ile gömülü şekilde gelmemektedir. Modülleri kullanmak için kurulması gerekmektedir.
Beautifulsoup modülü ise request modülü ile gelen html kodlarını düzenli bir şekilde göstermeye yarar.
Bu modüller python kurulumu ile gömülü şekilde gelmemektedir. Modülleri kullanmak için kurulması gerekmektedir.
- Beautiful Soup Python için bir HTML ve XML ayrıştırıcısıdır (parser). Beautiful Soup kütüphanesi kullanışlı olmasını şu özelliklerine borçludur:
- Beautiful Soup kötü girdi verseniz bile bozulmaz. Neredeyse orjinal belgenizle aynı anlama gelen bir ayrıştırma ağacı (parse tree) döndürür. Bu özellik çoğu zaman gereken bilgiyi almanız için yeterlidir.
- Beautiful Soup bir ayrıştırma ağacında kolayca gezinme (traversing), arama ve düzenleme yapmanıza olanak sağlayan birçok metot ve Python vari deyimler sağlar: her uygulama için baştan HTML veya XML ayrıştırıcı yazmanıza gerek kalmaz.
- Beautiful Soup gelen belgeleri Unicode'a, giden belgeleri de UTF-8'e kendiliğinden çevirir. Kodlamalarla uğraşmanıza gerek kalmaz.
BeautifulSoup ile web sitesinde veri çekmek için neye ihtiyacınız var?
BeautifulSoup ile çalışmaya başlamak için, makinenize Python programlama ortamı (yerel veya sunucu tabanlı) ayarlamanız gerekir. Python genellikle OS X'e önceden kurulmuştur, ancak Windows kullanıyorsanız resmi web sitesinden dili indirip yüklemeniz gerekir.
2.BeautifulSoup Modülü Kurulumu
Windows İşletim Sistemleri İçin kurulum ;
Cmd ekranını açınız ve aşağıdaki satırları yazarak kurunuz.
Windows İşletim Sistemleri İçin kurulum ;
- İlk önce pip install requests komudu ile requests kuruyoruz.
Kısaca requests modülünden bahsedecek olursak Python, standart modüllerinin yanında harici yüzlerce kullanışlı modül ile birlikte çok güçlü bir dil. Bu gücü veren harika modüller var bunlardan biri de Requests modülü.
Bu modül ile web
üzerindeki isteklerinizi yöneteceksiniz. Mesela bu modül ile API entpointlerine
PUT, DELETE, POST gibi istekler atabilirsiniz.

- İkinci olarak ise pip install beautifulsoup4 komudu ile BeatifulSoup modülümüzü kuruyoruz.

Linux İşletim Sistemleri İçin Kurulum;
Terminali açın python-setuptools
u kurunuz.
- sudo apt-get install python-setuptools
- sudo pip3
install requests
- sudo pip3 install beautifulsoup4
3.BeautifulSoup Modülü ile Web Sitesinden Verileri Çekme(Manuel)
Kurulumlar bittikten sonra requests ve beatifulsoup’u python da import ediyoruz.

İmport işlemleri başarılı bir şekilde tamamlandı.
Sıradaki işlemimi ise requests
ile web sitem olana https://baydarmazlum.blogspot.com/
‘a requests.get ile istek
atıyoruz.Giden istek nasıl cevap vermiş bunu görüntülemek için r.status_code komudu ile geri dönen
değerimize bakıyoruz. Aşağıda resimde de görüldüğü üzere 200 değerini döndürmüş yani başarılı bir şekilde geri dönüş
olmuş.Sayfanın kaynak kodunu çekip çekmediğini öğrenmek içi ise r.content komudunu kullanıyoruz ve
resimde görüldüğü üzere kaynak kodlar başarılı bir şekilde çekilmiş durumdadır.

soup = BeautifulSoup(r.content,"lxml") komutu ile alınan kaynak kodlarını BeatifulSoup içinde bulunan xlm modülü ile parçalayıp düzenli hale gelmesini sağladık.

Web sayfamın kaynağını görüntülediğim zaman blok blok her
birinin bilgisini görmekteyiz.Her class aslında bizim için birer veri
niteliğinde bunları tek tek ayırarak ayırma işlemi gerçekleştireceğiz.

soup.find("div",attrs={"class":"blog-post
hentry index-post"}) komutu find
metodu ile ilk bloğun verilerini çekmiş olduk.
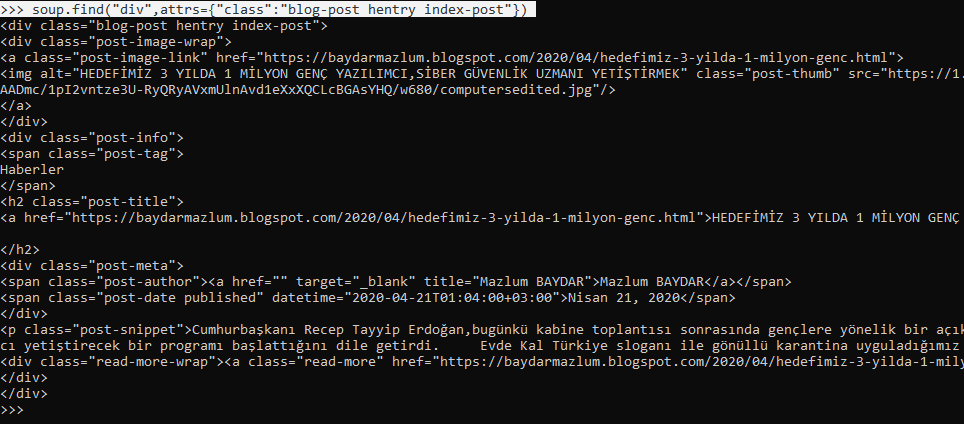
soup.find_all("div",attrs={"class":"blog-post
hentry index-post"}) komutunu kullanırsak bu sefer her bloğu ayrı ayrı
çekmiş oluruz.

Bir diğer veri çekme aşamamız web sayfasındaki bulunan blog
yazılarının başlıklarını çekmek üzere olacaktır. Bunun için
- for asd in bloglar:
- print(asd.h2.text)
Komutlarını kullanıyoruz. Bu komuttaki amacım öncelikle web sitesindeki kaynak kodlardan her bir başlığın barındığı konumu manuel olarak bulup(h2 olduğu ortaya çıkıt) bunları bir for döngüsü yardımıyla her birini ekrana yazdırmaktır.

4.BeautifulSoup Modülü ile Web Sitesinden Verileri Çekme (Kod Hali)

1.
Öncellikle requests
ve beatifulsoup modüllerini
import ediyoruz.
2.
r değişkenimize requests ile sitemizi tanımlıyıp
kaynak kodlarını çekiyoruz.
3.
Çektiğimiz kaynak kodlarını soup adında bir değişkene kodlarımızı daha derli toplu gözükmesi
için “lxml” formatına çeviriyoruz.
4.
Sekizince satır kodumuzda ise sitemizin kaynak
kodlarını bakarak istediğimiz bir bölümü bize find_all komudu ile getirmesini istiyoruz.
5.
Son olarak bir çok alanda veri çekme işlemi
yapmak için for döngüsünü kullanıyoruz.Çekmek
istediğimiz veriler,Sitedeki Makalelerin
İsmi,Yazarı,Makalelerin Yazılma Tarihleri ve Hangi Makaleler Hangi
Kategoridedir diyerek bu bilgileri düzenli olarak ekrana yazdıyoruz.
Ekran Çıktısı:




{kind=link}
0 Yorumlar